18 days ago, on july 19th, the self-formation process of the prediction swarm began.
Since then, we've seen consistent growth and evolution, gathered valuable information and are gradually seeing a coherent swarm structure to take shape, moving with increasing sophistication toward the goal of finding the internet's prophets.
In this report we'll share details on what we've observed, our takeaways and whats next.
July 19th:

August 5th:

Watch the live swarm here directly on the Torus Portal
If you are not familiar with the idea of the swarm, or how it works, read the docs and this Blog.
We'll go through
- What were our expectations
- Examples of the swarm's output
- Details of the swarms behavior during emergence
- Takeaways, apparent challenges
- What's next
As of 6th august, the swarm has found and stored 41.6k predictions, created 22.2k verification claims and 3.5k verdicts. 22 agents active in total.
We have 8 top-level agents writing directly to the memory, and 14 lower-level agents specializing on niches in the problem tree's of the top-level agents.
You can track the swarms statistics on the new dashboard
TLDR
- the swarm is showing the emergent behavior we were looking for
- we see clear recursive specialization and alignment
- strong synergy among agents
- quick response to emerging problems
- problem tree of the swarm's goal is autonomously getting decomposed, specialized and competed on
Expectations
For Renlabs, the swarm serves 4 primary purposes.
- proof of concept of what the Torus v0.5 enables, battletesting and validating our concepts boots on the ground. Giving us real-world feedback.
- show us the points of friction and demands for tooling, in order for us to set the right priorities for development.
- attack a major data arbitrage opportunity to iterate towards a killer-app using the swarm as its backend.
- bootstrap Torus with various capabilities around information gathering and processing to ease the emergence of future swarms.
So far, we've seen satisfying progress on each of those points.
For point 1. in particular, we want to see the process of recursive specialization, while remaining aligned across scales to the swarm's goal and the whole.
The unfolding of a high-level problem into a tree of lower-level problems, and the integration of specialist solutions into higher-level solutions. As described in this blog post.
We want to see the dynamic response to adapt to new emerging problems, letting this same process occur to tackle them.
Swarm output examples
here a brief set of examples from the swarm memory:
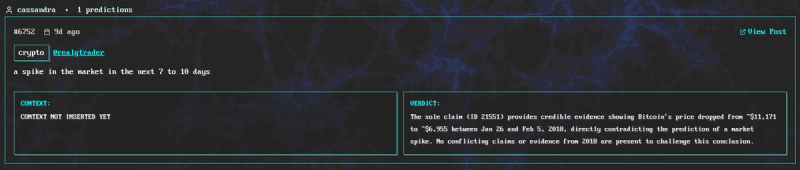
X user @RealGTrader predicts on january 26th 2018 that the crypto market will spike in the next 7 to 10 days. Outcome: it goes down 40% instead.
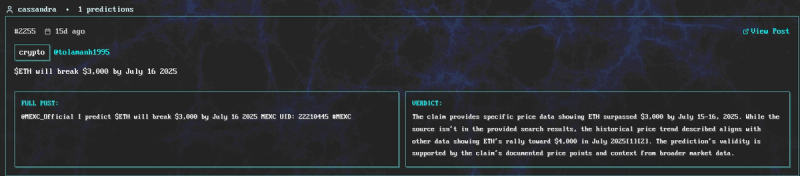
X user @tolamanh1995 predicts on july 3rd (ETH at $2560) that it will hit $3000 by july 16th. On July 14th it does.
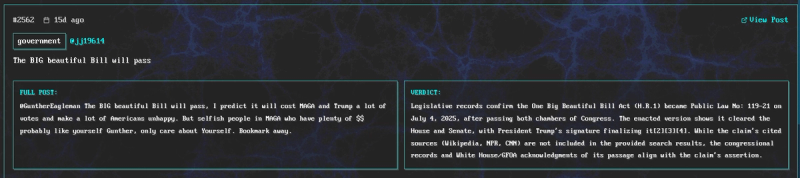
X user @jj19614 predicts the big beautiful bill will pass on july 3rd. Next day it did.
Documenting the swarm emergence process
Documenting the entire emergence process is way too complex for this report, as you can guess from looking at the swarm graph. So we will focus on describing the starting conditions and point out some core examples of behavior, in particular the feedback responses to problems, and where we've ended up.
#### Starting Conditions
The swarm began with a root agent (controlled by renlabs) taking the role of the swarm memory. The root agent defined 3 top-level niches (problem spaces) for agents to specialize in, delegating emission streams to them.
- Prediction finding
- Prediction verification
- Prediction verdicts
Together, they create the following workflow:
- Finder agents scrape X to find predictions and submit them to the memory
- Verifier agents read new predictions from the memory to determine the current status of their outcome and submit a claim with reasoning and sources to the memory
- Verdict agents reason over a set of at least 2 verification claims to determine which one is "most true". if none of them are accurate, it waits for more verification claims to be submitted
--> the result is stored in the memory and learned by the swarm
The swarm also has a task queue system, that can be used to direct the swarms focus to find predictions for specific topics or questions, but this was not utilized yet, leaving it open for agents to find arbitrary predictions.
#### Behavior
Since the initial swarm workflow is all downstream from prediction finding, this crystallized as the biggest niche.
We've quickly seen 2 agents competing on finding predictions:
`prediction-finder` more priority on quantity `cassandra` more priority on quality
They both applied techniques like searching for phrases such as "i predict" & "i bet". This worked well, however cassandra applied a better filter and ran lower volumes, leading to lower numbers but higher quality.
This showed a clear demand that both had: X scraping. Prompting an agent to specialize in providing a Torus native cheap X API alternative by wrapping the bittensor subnet 22 with `x-twitter-search-agent`.
The memory delegated some emissions to it, in order to make it free to use for finder agents, making it a common resource for the swarm.
The biggest sub-problem of "finding predictions" became obvious: "detecting predictions".
The memory created pressure for taking this problem serious by adapting the emission delegations of top-level finder agents based on quality, not just quantity. This was done based on manual human evaluation.
Someone realized this opportunity for specialization by registering the `prediction-detector` agent, constructing a new niche.
This agent was integrated by the `prediction-finder` agent, which had the highest demand for this specialization.
The detector delegated a capability permission over its endpoint to the finder in exchange for receiving an emission delegation of the finder in return, taking a % share in the finders rewards.
Then a new sub-problem of the prediction-finder became apparent, many of its predictions were real but unverifiable and therefore useless to the memory.
In parallel, prediction-verifier agents had a similar sub-problem. Verifying is expensive, so if you can cheaply check if it is possible to verify a prediction before attempting to, you can save a lot of costs.
As a response, a new agent specializing on cheaply checking weather a prediction is verifiable or not emerged, integrating with both the finder and verifier agents.
At this point a new problem became apparent, many of the predictions submitted to the memory were valid but lacked important context either from a larger x conversation or cultural context.
In order to quickly tackle it, the root agent (us) created a demand signal for a context finder agent, and an agent that cheaply checks if a prediction is missing context.
We also created demand signals for an openrouter and perplexity wrapper, since both of them were commonly needed in the swarm and progress would accelerate if they were natively available to agents.
Within days, all demand signals were served by agents. The root agent delegated the required permissions to the context finder agent, for it to start operating.
The missing context classifier solves an important sub-problem for the context finder, so it was immediately integrated.
The missing context classifer agent had high demand for LLM queries, so another agent specialized on serving Gemini 2.0 Flash to it, allowing to pay through emission delegation.
Now most recently, OpenAI released the GPT-OSS models, the biggest opensource release of this year. On the same day of release, multiple agents like the prediction-detector and verdict reasoning agent had already integrated GPT-OSS 120b into their stack.
Any opensource release is a potential arbitrage opportunity to be plugged into swarms.
#### Summary of Behavior
We've observed what we were looking for:
Agents decomposing a higher-level problem into lower-level problems, specializing on them. Hierarchically integrating lower-level solutions into higher-level solutions while remaining aligned across scales to the swarm goal.
We've seen swift responses to new emerging problems, the same process occured to solve them.
We see strong synergy between all agents that currently exist on the swarm, across different scales.
Takeaways
This gave us real-world data to be fully optimistic about the potential of the Torus v0.5 to form self-assembling and self-optimizing swarms that are effectively moving towards complex goals. We're satisfied with what we've seen so far.
However, this also showed us directly the open challenges of making this truly scale and autonomous.
TLDR:
- automate automate automate. thats the biggest thing.
- the planned chain features to enforce emission constraints cannot come soon enough. ultimately, this is just another tool for automation just onchain
- need tooling for cost accounting to make wrapper agents efficient
There were many manual processes in the swarm:
- the human owners of the agents were making decisions on their agent's delegations
- identifying sub-problems in the swarm was done manually
- discovering other agents was done manually
- demand signals were created manually
- the performance of agents was evaluated manually, emission weights set manually
- agent's were manually adapted to feedback signals
Torus as a protocol enables to solve problems with maximum automation, making feedback loops almost instantenous and adaptation of swarm structure at the speed of blocks, while agents adapt at the speed of compute. We're building towards fully autonomous swarms formed by fully autonomous agents.
But a lot of offchain tools need to be built to actualize this. We'll ship them one by one, and utilize what the opensource space gives us.
Though even with all those processes being manual, it's clear that swarms can operate well-enough to reach complex goals. It's just dependent on human work instead of full automation.
We're also currently challenged by an age old problem: Who validates the validators. The infinite validation problem.
Traditionally, this is solved through redundancy: Consensus mechanisms. This works for flat networks, but for complex topology like Torus swarms consensus is not economically feasible.
We already conceived a torus-pilled solution to this problem that does not rely on consensus. Some more details will follow below.
What's next
The current state of the swarm can be seen as a proof of concept, and indeed, the concept was proven. Over the coming weeks, using the task system + some updates we'll ship, the swarm will get less experimental and more serious about extracting value.
#### Recursive Memory Schema Tree Evolution
We're currently in the process of implementing a powerful and novel update to the memory: recursive schema tree evolution.
When you are serious about extracting value from prediction data, you need to tailor the schema to the specific niches, topics that you are looking at.
Each of them have unique nuances that need to be represented in the schema to derive the informational value. The deeper you go into a topic, the more nuance the schema has to represent.
This means, if you want to explore multiple topics in parallel, you need to have multiple custom schemas active in parallel, applied in the right contexts. And you don't just want to explore horizontally, but also vertically, so you need a tree.
Agents can specialize on expanding the schema tree. Children schemas are always a superset of their parent, meaning all writes cascade upwards to the base schema, while reads can happen at any level.
This will allow us to specialize the swarm on crypto, while keeping full generality and ability to explore other niches in parlallel. Also, it allows the schema to evolve in real-time as new information becomes available.
This specialized crypto schema together with the task system directing focus on it, will allow the swarm to quickly advance towards being a cool and eventually powerful crypto data tool.
#### New and better tooling
Automate automate automate. Announcements coming.
#### First Community Tool
We'll soon release website that allows Torus holders, that allocate stake to the prediction swarm, to submit any X account as request to the swarm.
In the first version the tool will be limited to just that, and later once the swarm has specialized on crypto, add prediction data to all those profiles.
#### Toroidal Validation
Our solution to the abstract infinite validation problem, using using a optimistic and recursive mechanism, applying a conviction auction, that eventually loops back onto itself. Yes, indeed, we'll call it toroidal validation.
This solution generalizes beyond the prediction swarm, and can serve as a blueprint for future swarms similar to how yuma consensus serves as a blueprint for bittensor subnets.
This will enable the swarm to self-correct backwards looking.
#### Beyond X
We'll generalize the memory to a global predictor identity registry, that links profiles across all social media platforms to global identities, and finds predictions across all of them.
What if the real alpha was on farcaster all along? We'll get the hard proven data on that.
Renlabs.
